

本发明涉及大数据查询处理领域,具体涉及大数据平台物化视图的查询处理方法及系统。

背景技术:
随着智能电网建设不断深入与推进,电网运行和设备监测产生的数据量呈指数增长,电网企业所能储存、处理的数据已经达到前所未有的量级,并且以超过摩尔定律的速度迅猛增加。大数据最核心的价值就是在于对于海量数据进行存储和分析。在商业环境下,数据处理服务提供商将大数据处理包装成服务,出售给用户。随着大数据商业化应用的发展,其数据处理出现了以下特征:
1)大数据平台用户数量巨大。大数据服务提供商希望为更多的客户服务,以获取更多的商业利润。
2)用户对大数据分析处理的性能要求呈现多样化特点。有的用户实时化分析需求多一些,而有的用户对查询的返回时间不是特别在意。对于一些实时的数据分析需求,用户对处理的性能及返回的时间有所要求。通常的做法是,用户与大数据服务提供商签订一个关于返回时间的协定。返回时间越早,服务提供商的收益越高;反之,返回时间越迟,收益越低,甚至需要支持一定的惩罚性的金额。
3)大数据平台需要处理大量用户发起的大量分析性查询,因此其需要依赖云计算平台完成各种数据及事务的处理。
大数据平台能够服务众多用户提供数据分析处理服务并为服务提供商带来利润。然而,大数据平台的分析查询中,存在大量连接操作,这种操作比较费时。将一部分常用的、关键的连接中间结果存储到外存储器中,可以使用查询避免连接操作,从而达到缩短返回时间的目的。我们称这种中间结果的数据为物化视图。物化视图占用存储空间较大,虽然大数据平台有较大的存储空间,但不可能提供无限的物化视图存储空间。因此我们需要对各项视图进行选择,将常用的、关键的视图进行物化。上述的大数据平台是若干服务器组成的云计算环境,实质为服务器集群。
在Share-Nothing的结构云计算平台中,每个计算节点都具备存储功能,每个节点都需要保留一定存储空间存储物化视图。选择好的物化视图需要放置到各节点中去。不同的放置方法,会对分析查询有不同的优化效果。因此本发明专利还提供一种物化视图的放置方法。
技术实现要素:
为解决现有技术存在的不足,本发明公开了大数据平台物化视图的查询处理方法及系统,大数据平台物化视图的查询处理方法包括物化视图选择方法、物化视图放置方法。物化视图的选择方法是物化视图放置方法的基础,物化视图的选择为物化视图算法提供输入标的,即输入需要放置的物化视图集合,可以减少节点间的网络数据传输,缩短处理时间。
为实现上述目的,本发明的具体方案如下:
大数据平台物化视图的查询处理方法,包括:
物化视图的选择步骤:针对给定的查询集合生成MVPP结构图,根据该结构图得到所有非叶节点的集合,计算该集合中每个非叶节点的价值,利用面向收益最大化的物化视图贪心选择算法获得物化视图集合;
物化视图的放置步骤:针对物化视图的选择步骤获得的物化视图集合建立物化视图关联权重矩阵,计算矩阵中每个元素的值,将所有计算节点按物化存储空间按大小降序排列,在所有计算节点中取物化存储空间最大的节点,获得放置到该节点的物化视图。
进一步的,针对给定的查询集合,利用MVPP算法利用生成MVPP结构图,通过有向无环图的形式来表述针对查询集的整体查询处理策略。
进一步的,在MVPP结构图中,用叶结点表示的是数据库中的事实表,而根节点则表示的是基于事实表的查询,所有非叶节点都可以作为物化视图的选择对象。
进一步的,设E为MVPP结构图中所有非叶节点的集合,在MVPP结构图中,一个非叶节点用ej表示,每个非叶节点ej都对应一个候选物化视图,用mj表示ej非叶节点代表的候选物化视图。
进一步的,非叶节点ej的价值用υj表示,其计算方法为:
ti,j为当ej对应的候选物化视图mj已经物化时qi的返回时间,ti,j通过测试得到,Qj为可以依赖mj完成查询处理的查询集合,ai为初始收益,即一个查询qi能够立即返回的收益,bi为惩罚斜率,其代表随时间流逝收益下降的速率,ti为一个查询qi的返回时间。
进一步的,面向收益最大化的物化视图贪心选择算法是基于价值化MVPP图的选择算法,其输入是计算了每个非叶节点的价值的MVPP图,输出为一个物化视图集合。
进一步的,面向收益最大化的物化视图贪心选择算法的具体步骤为:
1)设F为一个物化视图集合,并初始化为空;
2)计算取得E中υj/sj最大的非叶节点ej,其中sj为ej对应候选物化视图所占用的存储空间大小,非叶节点ej的价值用υj表示;
3)将ej对应的候选物化视图加入F,即对mj进行物化,形式化表达为:F←F∪mj,E←E-ej;
4)更新E中其他非叶节点的价值;
5)若F的物化视图占用的存储空间之和小于系统物化视图总存储空间S,则重复执行第2)步;否则结束算法,F即为所求物化视图的集合。
进一步的,所述步骤4)中具体的更新操作步骤:
对可依赖mj执行查询集合Qj,对于Qj中每一个查询qi执行以下操作:qi返回时间ti更新为基于mj执行查询处理的返回时间;
由于物化mj后,会影响ej子孙非叶节点和祖先非叶节点的价值,根据非叶节点ej的价值用计算公式重新计算ej的子孙非叶节点与祖先非叶节点的价值。
进一步的,物化视图关联权重矩阵H中,H有|F|行与|F|列,设hi,j为H的一个元素,那么hi,j则表示mi与mj两个物化视图的关联权重,|F|要放置物化视图的数量。
进一步的,计算H中每个元素的值,其计算方法为:在上式中,bk是指qk收益函数中的惩罚斜率;Qi,j是指在Q中在查询处理时需要同时访问mi与mj两个物化视图的查询的集合。
进一步的,用N表示云中计算节点集合,|N|为计算节点的数量,设计算节点nk的物化视图存储空间大小为sk,在N取物化存储空间最大的nk,通过计算获得放置到该节点的物化视图,计算方法为:
a)在H中,从|F|行选择行和最大的物化视图mi作为初始聚类中心;
b)将mi放置到nk;
c)在F依次取出与mi关系权重最大的mj,将mj放置到nk,直到放置到nk的物化视图占用的存储空间大于sk。
进一步的,在获得放置到该节点的物化视图步骤之后,执行N←N-nk步骤,然后重复执行通过计算获得放置到该节点的物化视图的步骤,直至
大数据平台物化视图的查询处理系统,包括:
物化视图的选择模块:针对给定的查询集合生成MVPP结构图,根据该结构图得到所有非叶节点的集合,计算该集合中每个非叶节点的价值,利用面向收益最大化的物化视图贪心选择算法获得物化视图集合;
物化视图的放置模块:针对物化视图的选择步骤获得的物化视图集合建立物化视图关联权重矩阵,计算矩阵中每个元素的值,将所有计算节点按物化存储空间按大小降序排列,在所有计算节点中取物化存储空间最大的节点,获得放置到该节点的物化视图。
本发明的有益效果:
本发明的给出一种大数据物化视图选择方法与云中物化视图放置方法,最大化大数据平台服务提供商的收益。
本发明量化了各物化视图对收益的影响,为物化视图的选择提供准确的支持。
本发明的物化视图放置方法可以减少节点间的网络数据传输,缩短处理时间。
本发明的物化视图的选择与放置能够适应大规模数据处理环境,并且易于在云计算环境中扩展。
本发明可以适应云中各节点物化存储空间大小异构的场景。
附图说明
图1 MVPP结构图;
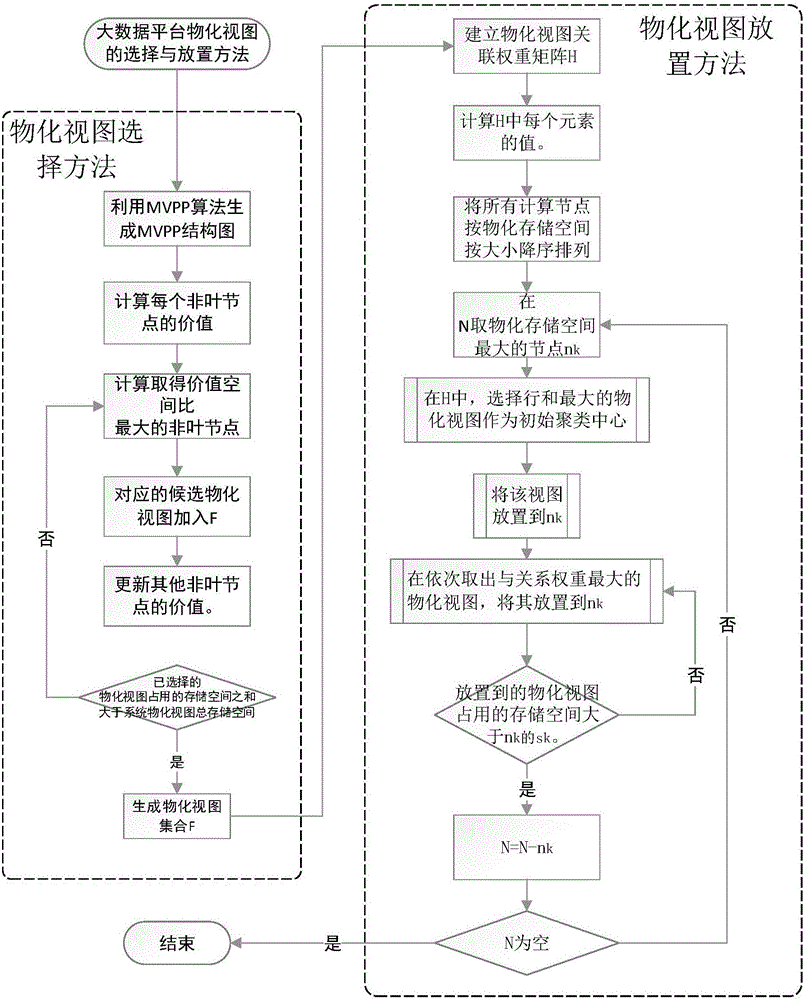
图2本发明的大数据平台物化视图的选择及放置流程图。
具体实施方式:
下面结合附图对本发明进行详细说明:
如图2所示,本发明专利的大数据平台物化视图的查询处理方法具体实施主要分为两个部分:物化视图选择方法及物化视图放置方法。
一、物化视图选择方法:
1)因为每个周期的大数据查询有所变化,因此周期的进行物化视图选择。
2)在云计算节点中,任意选择一个计算节点作为主节点,其收集上一个周期的查询集合。
3)将查询集合生成MVPP结构图。全部查询处理计划(Multi-View Processing Plan,简记为MVPP),通过有向无环图的形式来表述针对查询集的整体查询处理策略。图1中用叶结点表示的是数据库中的事实表,而根节点则表示的是基于事实表的查询。所有非叶节点都可以作为物化视图的选择对象。
在图1中,以Q1、Q2、Q3、Q4、Q5为例,呈现了他们生成的MVPP结构图。如查询Q3是由表Item、Sale和Part连接而得,即(Item∞Sale)∞Part。当查询数量较多时,这样的可能的查询计划就越多,而且非叶节点会膨胀很快。因此只能对部分视图进行物化。将查询集合生成MVPP结构图具体参见文献:J.Yang,K.Karlapalem,and Q.Li,"Algorithms for materialized view design in data warehousing environment,"in VLDB,1997,pp.136-145.
4)利用公式(3)计算每一个非叶节点的价值。
设E为MVPP结构图中所有非叶节点的集合。在MVPP中,一个非叶节点用ej表示。每个非叶节点ej都对应一个候选物化视图,用mj表示ej非叶节点代表的候选物化视图。
以收益最大化为目标的物化视图的选择与放置方法与查询的收益函数密切相关。首先给出分析查询的收益函数。一个查询用qi表示,i是该查询的编号。设一个查询的收益函数为R,那么根据qi的参数计算R的方法为
R(ti)=ai-bi×ti (1)
在公式1中,ai为初始收益,即qi能够立即返回的收益。bi为惩罚斜率,其代表随时间流逝收益下降的速率。ti为qi的返回时间。
非叶节点ej的价值用υj表示,其计算方法为:
根据公式(1)进一步推导为:
ti,j为当ej对应的候选物化视图mj已经物化时qi的返回时间,ti,j通过测试得到。Qj为可以依赖mj完成查询处理的查询集合。
5)利用面向收益最大化的物化视图贪心选择算法获得物化视图集合。面向收益最大化的物化视图贪心选择算法是本发明专利提出的一种基于价值化MVPP图的选择算法,其输入是计算了每个非叶节点的价值的MVPP图,输出为一个物化视图集合,其主要步骤如下:
(1)设F为一个物化视图集合,并初始化为空。
(2)计算取得E中υj/sj最大的非叶节点ej,其中sj为ej对应候选物化视图所占用的存储空间大小。
(3)将ej对应的候选物化视图加入F,即对mj进行物化。也即:F←F∪mj,E←E-ej。
(4)更新E中其他非叶节点的价值。由于将mj物化后,一些查询的返回时间会发生变化,从而导致某些非叶节点的价值会发生变化,因此需要价值更新操作。
以下更新操作的具体步骤:
a)对可依赖mj执行查询集合Qj,对于Qj中每一个查询qi执行以下操作。qi返回时间ti更新为基于mj执行查询处理的返回时间。
b)由于物化mj后,会影响的ej子孙非叶节点和祖先非叶节点的价值。根据公式(3)重新计算ej的子孙非叶节点与祖先非叶节点的价值。
(5)若F的物化视图占用的存储空间之和小于系统物化视图总存储空间S,则重复执行第2)步;否则结束算法,F即为所求物化视图的集合。
二、物化视图放置方法
在进行查询处理时,可能会用到两个或者以上的物化视图。当这些查询视图分布在多个节点时,会产生较大数据传输成本,从而降低查询处理速率。因此本发明专利提出一种基于关联权重的物化视图放置算法。关联权重是指两个物化视图被一个查询同时访问的频率值。
用N表示云中计算节点集合,|N|为计算节点的数量。设计算节点nk的物化视图存储空间大小为sk。基于关联权重的物化视图放置算法的主要步骤如下:
1)主计算节点负责分配物化视图,其他计算节点负责接收与存储物化视图。
2)建立物化视图关联权重矩阵H。H有|F|行与|F|列,设hi,j为H的一个元素,那么hi,j则表示mi与mj两个物化视图的关联权重。|F|要放置物化视图的数量。
3)计算H中每个元素的值。如hi,j,其计算方法为:在上式中,bk是指qk收益函数(公式(1))中的惩罚斜率;Qi,j是指在Q中的一些查询,这些查询在处理时,需要同时访问mi与mj两个物化视图。
4)将所有计算节点按物化存储空间按大小降序排列。
5)在N取物化存储空间最大的nk,通过计算获得放置到该节点的物化视图。计算方法为:
i.在H中,从|F|行选择行和最大的物化视图mi作为初始聚类中心。
ii.将mi放置到nk。
iii.在F依次取出与mi关系权重最大的mj。将mj放置到nk,直到放置到nk的物化视图占用的存储空间大于sk。
6)N←N-nk,即将节点nk,从候选节点集合中删除。
7)重复执行第5)步,直到
本发明还公开了大数据平台物化视图的查询处理系统,包括:
物化视图的选择模块:针对给定的查询集合生成MVPP结构图,根据该结构图得到所有非叶节点的集合,计算该集合中每个非叶节点的价值,利用面向收益最大化的物化视图贪心选择算法获得物化视图集合;
物化视图的放置模块:针对物化视图的选择步骤获得的物化视图集合建立物化视图关联权重矩阵,计算矩阵中每个元素的值,将所有计算节点按物化存储空间按大小降序排列,在所有计算节点中取物化存储空间最大的节点,获得放置到该节点的物化视图。
本发明的上述系统中物化视图的选择模块所实现的功能依靠上述物化视图的选择方法的具体的步骤及算法来实现,物化视图的放置模块的功能的实现依靠上述物化视图的放置方法的具体的步骤及算法来实现。